Exercices sur l'ordonnancement
Préambule
Le schéma de base d'utilisation de fork() a été vu en cours et il est disponible en suivant ce lien : http://www-lipn.univ-paris13.fr/~cerin/SE/fork1.c On modifie le schéma comme suit :
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
}
else { /* parent process */
/* parent will wait for the child to complete */
printf("titi");
wait(NULL);
exit(0);
}
}Comme il y a un test dans le programme, soit le printf(toto) soit le printf(titi) aura lieu. Etes vous d'accord avec cela ? Si ce n'est pas le cas, expliquez ce qui va se passer à l'exécution.
On propose maintenant le code suivant et nous affirmons que l'affichage ne peut être que toto suivi de titi suivi de tata ou titi suivi de toto suivi de tata. On ne peut jamais avoir comme premier affichage tata. Etes vous d'accord avec ces affirmations ?
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
}
else { /* parent process */
/* parent will wait for the child to complete */
printf("titi");
wait(NULL);
printf("tata");
exit(0);
}
}
On modifie de nouveaux le schéma de base comme suit :
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int status;
pid_t wpid, pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
printf("toto");
wpid = waitpid(getppid(), &status, WNOHANG);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("tata");
exit(0);
}
}Cette implémentation utilise la fonction waitpid qui permet de contrôler la terminaison d'un processus particulier. Que va t'il se passer avec le code donné ? Attention, il faut bien voir ici que l'instruction waitpid n'est pas bloquante (faire un man waitpid).
- Ordonnancement
L'algorithme d'ordonnancement des processus le plus simple est l'algorithme du premier entré, premier sorti (FCFS: First Come, First Serve). Les processus sont ordonnancés dans l'ordre où ils sont reçus. Cet algorithme n'est pas préemptif : une tâche qui a débuté, termine avant que l'on passe la main à la suivante.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de requêtes d'I/O ?
L'algorithme du travail le plus court d'abord (SJF: Shortest Job first) est également non-préemptif. Il sélectionne le processus dont il suppose que le temps de traitement sera le plus court. En cas d'égalité, l'ordonnancement FCFS peut être utilisé.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de travaux de courtes durées et peu de travaux de longues durées ?
L'algorithme du temps restant le plus court (SRT: Shortest Remaining Time) est la version préemptive de l'algorithme SJF. Chaque fois qu'un nouveau processus est introduit dans le pool de processus à ordonnancer, l'ordonnanceur compare la valeur estimée de temps de traitement restant à celle du processus en court d'ordonnancement. Si ce temps est inférieur, le processus en cours d'ordonnancement est préempté.
Quels sont les inconvénients de cette approche si les processus (tâches) à accomplir comportent beaucoup de travaux de courtes durées et peu de travaux de longues durées ?
L'algorithme à tourniquet (RR: Round robin) est un algorithme préemptif qui sélectionne le processus qui attend depuis le plus longtemps. Après un quantum de temps spécifié, le processus en cours d'exécution est préempté et une nouvelle sélection est effectuée. Si le quantum de temps est très court, la réponse du système est bonne. Cependant, plus on change souvent de contexte, plus les surcoûts peuvent prendre de l'importance (d'où l'importance d'avoir du matériel dédié pour implémenter efficacement cette notion).
L'algorithme avec priorité requiert qu'une valeur (dite de priorité) soit associée à chaque processus. Le processus sélectionné est celui avec la plus haute priorité. C'est l'algorithme FCFS qui est utilisé en cas d'égalité. L'ordonnancement des priorités peut être préemptif ou non.
Les mécanismes d'attribution des priorités sont très variables : bassés sur la caractéristique des processus (utilisation de la mémoire ; fréquence des I/O), sur l'utilisateur qui exécute le processus (les processus root ont une priorité plus élevée) ou encore sur les paramètres que l'utilisateur ou l'administrateur peut spécifier.
Exercice sur les performances
Soient les données d'ordonnancement suivantes :
|
Processus |
Date d'arrivée |
Temps de traitement |
|
A |
0 |
5 |
|
B |
1 |
2 |
|
C |
2 |
5 |
|
D |
3 |
3 |
Quel est le déroulement de l'exécution des processus pour l'algorithme SRT ? (on préempte à chaque unité de temps). Même question pour l'algorithme du tourniquet.
Le temps de rotation de chaque processus peut être calculé en soustrayant la date à laquelle le processus a été introduit dans le système à la date à laquelle celui-ci a pris fin. Calculez les temps de rotation des 4 processus précédents et pour les deux algorithmes (SRT et RR).
Le temps de rotation moyen est alors calculé en faisant la somme des temps de rotation et en divisant par le nombre de processus concernés. Calculez les deux temps moyen. En déduire l'algorithme le « meilleur ».
Exercice sur les algorithmes d'ordonnancement
Avec les processus répertoriés dans le tableau qui suit, dessinez un schéma illustrant leur exécution à l'aide des algorithmes FCFS, SJF, SRT, RR (quantum = 2), RR (quantum = 1).
|
Processus |
Date d'arrivée |
Temps de traitement |
|
A |
0,00 |
3 |
|
B |
1,001 |
6 |
|
C |
4,001 |
4 |
|
D |
6,001 |
2 |
Calculez également pour chaque algorithme les temps moyens de rotation.
Le temps d'attente peut être calculé en soustrayant la durée d'exécution du temps de rotation. Calculez les temps d'attente pour les 4 processus précédents.
Autres algorithmes d'ordonnancement
a) Considérons de nouveaux la politique SJF. A la différence de précédemment, ici le temps de traitement de la tâche Ti n'est pas connue à l'avance mais il est estimé en fonction de la durée d'exécution précédente de la tâche. L'estimation peut être faite par :
On considère a=0.8 et T0=2. Tracer les deux fonctions correspondantes aux deux estimations ci-dessus. Considérez alors qu'une seule et même tâche arrive dans le système toutes les 2 unités de temps (c'est périodique) et dure 1.5 unité de temps. Quel sera l'ordonnancement de ces tâches si on considère la première puis la deuxième estimation ?
b) Considérons maintenant la politique HRRN (Highest Response Time Next). Cette politique calcule la quantité suivante RR=(w+s)/s où w est le temps passé à attendre le processeur et s est l'estimation du temps d'exécution ou de service (calculé au moyen des formules ci-dessus). La règle d'ordonnancement est alors la suivante : quand le processus courant est terminé (ou bloqué), choisir le processus avec la plus grande valeur RR.
Cette approche se caractérise par la prise en compte de « l'âge » des processus tout en accordant plus d'importance aux « petits » processus (« un petit s produit un grand RR »).
Reprenez l'exemple du a) et donnez l'ordonnancement.
Ordonnancement selon la charge
Supposez
que vous avez une machine multicoeurs et des tâches à
ordonnancer. Nous proposons de faire fonctionner l'ordonnanceur de la
façon suivante afin d'équilibrer les charges :
Ordonnanceur:
while(tue) AlgoA endwhile
AlgoA:
a) L = les k tâches les plus grosses (celles qui
occupent le plus les CPU) en considérant globalement la situation
b) Redistribution : prendre aléatoirement une à une les tâches de L
et les placer sur le coeur le moins chargé
On peut montrer que l'algorithme précédent est à un facteur 2 de
l'optimal ce qui veut dire par exemple que si la charge optimale est de 50% alors
l'algorithme nous amenera au pire à une situation ou la charge est
100%. Une constante 2 est favorable.
1- Faites tourner trois itérations de l'algorithme sur l'exemple numérique suivant avec k=4 :
coeur 1 : 21%, 20%, 12%, 7%, 6% -- charge de 66% coeur 2 : 21%, 17%, 16%, 4% -- charge de 58% coeur 3 : 18%, 17%, 13%, 3%, 3% -- charge de 54% coeur 4 : 19%, 18%, 12%, 8% -- charge de 57%2- Placer les 18 tâches de départ de manière optimale, c'est à dire en faisant en sorte que la charge soit la plus petite possible en équilibrant au mieux. Vous pouvez procéder en triant les tâches puis en plaçant les plus grosses puis les plus petites (ou bien l'inverse). Vérifier que l'algorithme fournit une solution à 2 de l'optimale. (Solution optimale : 60% de charge maximale)
Calcul du nombre de processus créés.
Dans le cours, il y a un exemple d'une boucle pour dans laquelle on a une instruction fork(). Nous avons remarqué que si on enlève l'instruction exit ou break dans le fils, alors il n'y a pas n processus de crées mais plus.
On vous demande d'exprimer C(n) (nombre de processus créés en fonction de la borne n de la boucle pour) en fonction de n. Pour cela, considérez les cas n=1, n=2, n=3 puis conjecturez une solution pour C(n). Montrez alors l'héritage de la propriété c.à.d C(n) => C(n+1).
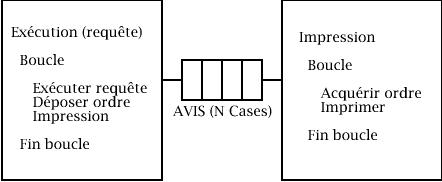
Synchronisation
Soit un système composé de deux processus cycliques Exécution et Impression, et d'un tampon AVIS de n cases. Le tampon AVIS est géré de façon circulaire.
Le processus Exécution exécute une requête de travail et transmet ensuite au processus Impression un ordre d'impression de résultats déposé dans le tampon AVIS. La case de dépôt est repérée par un index i de dépôt, initialisé à 1. Les dépôts s'effectuent depuis la case 1 jusqu'à la case N, puis retour à la case 1 (gestion circulaire).
Le processus Impression prélève les ordres d'impression déposés dans le tampon AVIS et exécute ceux-ci. La case de retrait est repérée par un index j de retrait, initialisé à 1. Les retraits s'effectuent depuis la case 1 jusqu'à la case N, puis retour à la case 1 (gestion circulaire).
Programmez la synchronisation des deux processus à l'aide des sémaphores et des variables nécessaires à la gestion des tampons.
Parallélisme / concurrence
Supposons que le tableau B[0,j] ait été rempli avec les entiers 1...n. Supposons que l'on dispose de n processeurs et que l'instruction pardo permet d'exécuter des instructions en parallèle (en « vrai » parallélisme, pas en temps partagé !). Que va t'on calculer dans le tableau C avec l'algorithme ci-dessous ? (on suppose de plus que n est une puissance de 2)

Donnez les contenus du tableau C entre chaque itération.